一、为什么使用索引
1.索引是存储引擎用于快速找到记录的一种数据结构。相当于一本书的目录。在进行数据查找时,首先查看查询条件是否命中某条索引,符合则通过索引查找相关数据。如果不符合则需要全表扫描,一条一条查找记录,直到找到与条件符合的记录。
2.创建索引减少磁盘的I/O的次数,加快查询速度。
二、索引的优缺点
1.索引概述
①索引是MySQL高效获取数据的数据结构
②索引的本质:索引是数据结构,排好序的快速查找的数据结构
③索引是在存储引擎实现的,每种存储引擎不一定支持所有的索引类型。存储引擎定义表的最大索引数和最大索引长度。
2.索引优点
①索引提高数据检索的效率,降低数据库的IO成本
②通过创建唯一索引,保证数据库表每一行的数据唯一性
③加速表和表之间的连接,对于有依赖关系的子表和父表联合查询时,可以提高查询速度
④使用分组和排序子句进行查询数据时,显著减少查询分组和排序的时间,降低CPU消耗
3.索引缺点
①创建索引和维护索引耗费时间,随着数据量增加,所耗费的时间增加
②索引占磁盘空间,存储在磁盘上
③索引提高查询速度,同时降低更新表的速度,在表中的数据增加,删除,修改,索引动态维护,降低数据的维护速度。
4.索引的提示
索引提高查询的速度,会影响插入的速度。这种情况下,最好的办法是先删除表中的索引,然后插入数据,插入完成再创建索引
三、InnoDB索引的推演
3.1没有索引情况下查找
3.1.1.在一个页查找
①主键查找
select *
from employees
where employee_id=101;
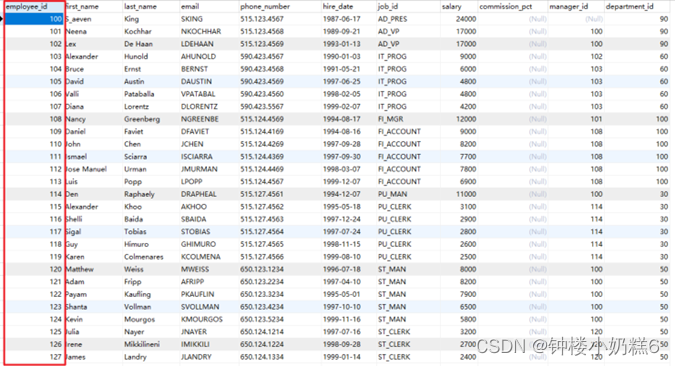
在页目录使用二分法快速定位到对应的槽,然后再遍历槽对应分组的记录,快速找到指定的记录
②其他列作为条件(非主键的列)
select *
from employees
where last_name='Abel';
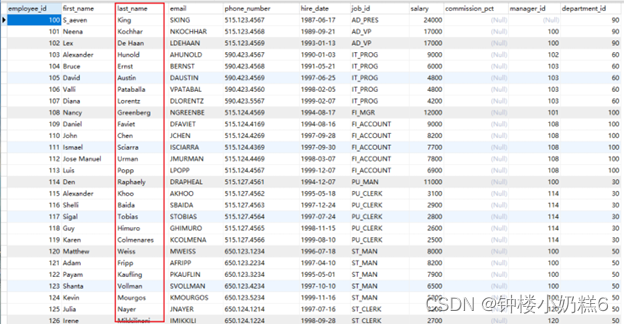
只能从最小记录开始依次遍历单链表中的每条记录,判断是否符合条件,效率低。
3.1.2.在很多页查找
①定义到记录所在的页
②从所在的页查找对应的记录
没有索引情况下,不论根据主键还是其他列,只能从第一页沿着双向链表一直往下找,在每个页根据上面的查找方法查找指定的记录。非常耗时,所以索引来了。
3.2设计索引
建一个表
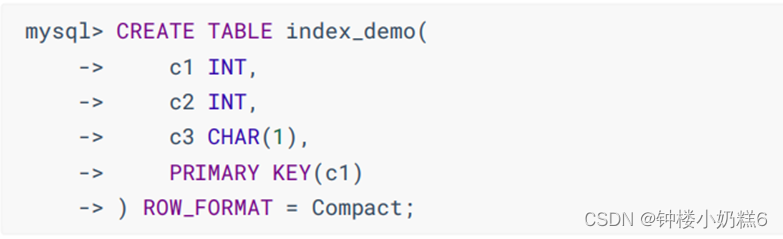
①index_demo表的行格式示意图

record_type:0是普通记录,2是最小记录,3是最大记录
next_record:记录下一条数据的地址
②把一些记录存放到表里的示意图

3.2.1简单的索引设计方案
问题:想快速定位到需要查找的数据在哪些数据页,可以为数据页建立一个目录:
①所有数据页里面的记录的主键是递增的

②为数据页建立目录:当前页的主键最小值key,当前页号page_no

此时把目录项在物理存储器连续存储,实现主键快速查找某条记录的功能。
比如:查找主键20
①先从目录项根据二分法快速确定主键值为20在目录3中(12<20<209)
②在页中查找记录方法根据主键值二分法查找具体的记录
3.2.2InnoDB中的索引方案
①迭代1次:目录项记录的页,采用单向链表实现,便于增加和删除

record_type=1表示存放的是目录项
record_type=0 表示存放的是普通记录
目录项记录和普通用户记录的相同点:都会为主键值生成Page Directory(页目录),按照主键值进行查找时使用二分法加快查询速度。
比如:查找主键20
先从页30中通过二分法快速定位到对应目录项,因为(12<20<209),定位到页9
从页9使用二分法定位到主键值为20的用户记录
②迭代2次:多个目录项记录的页,双向链表
假设目录项记录的页最大记录是4,现在新添加的记录,所以要生成新的目录项的页

比如:查找主键20
确定目录项记录页,现在目录项页30和页32,页30的主键值范围是[1,320),页32是不小于320,所以在页30
通过目录项记录页根据二分法查找出对应的目录项,定位页9
在页9通过二分法定位到主键20的用户记录
③迭代3次:目录项记录页的目录页,大目录嵌套小目录

生成存储高级目录项的页33,这个页中的两条记录代表页30和页32。
④这个结构就是B+树
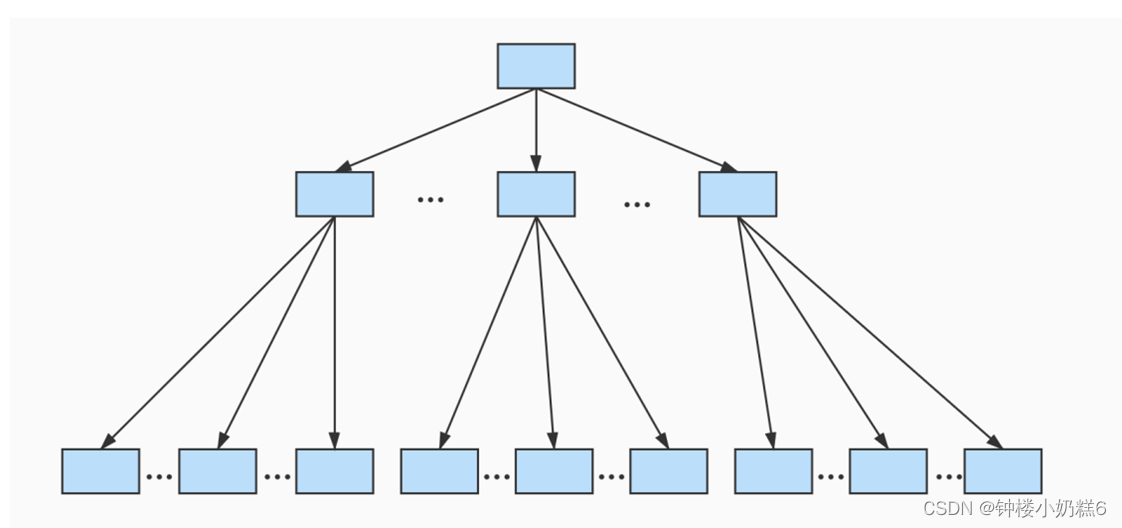
B+树都不会超过4层,通过主键值查找某条记录最多需要4个页面内的查找。(3个目录项页,1个用户记录页),每个页面有page Directory页目录,可以通过二分法快速定位记录。
假设:普通数据页:100条用户记录 目录项记录页:1000条目录项记录
如果B+树只有1层,只有1个存放用户记录的节点,最多能存放 100 条记录。
如果B+树有2层,最多能存放 1000×100=10,0000 条记录。
如果B+树有3层,最多能存放 1000×1000×100=1,0000,0000 条记录。
如果B+树有4层,最多能存放 1000×1000×1000×100=1000,0000,0000 条记录
3.3常见索引的概念
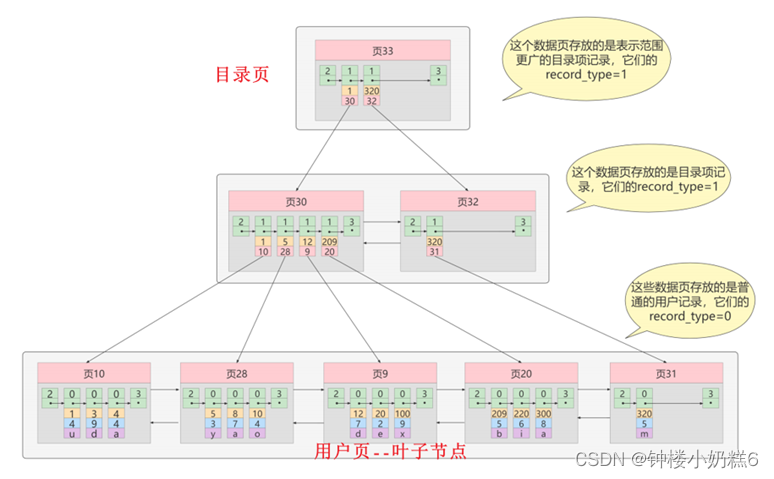
3.3.1聚簇索引:主键构建的B+树
概念:
聚簇索引是一种数据存储方式,所有的用户记录都在叶子节点,索引即数据,数据即索引。
聚簇表示数据行和相邻的键值聚簇的存储在一起。InnoDB存储引擎会自动创建聚簇索引
特点:
①页内记录按照主键的大小排序成一个单向链表,有序的
②存放记录的页按照主键值大小顺序排成一个双向链表
③存放目录项记录的页按照主键值顺序排成一个双向链表
④B+树的叶子节点存储的是完整的用户记录
优点:
①数据访问快,聚簇索引将索引和数据保存在同一个B+树中。B+树的叶子节点就是完整的用户记录
②因为按照主键大小排序成一个单链表,排序查找和范围查找速度快
③查找范围的数据时,数据紧密相连,节省了大量IO操作
缺点:
①插入速度严重依赖插入顺序,否则会出现页的分裂,影响性能。因此InnoDB表,定义一个自增的ID列作为主键
②更新主键的代价很高。会导致更新行的移动。对于InnoDB表,定义主键不可更新
③二级索引访问需要两次索引查找,第一次找到主键值,第二次根据主键值找到行数据。
限制:
①InnoDB支持聚簇索引,MyISAM不支持聚簇索引
②每个表只能有一个聚簇索引,该表的主键
③没有定义主键,InnoDB选择非空的唯一索引代替。没有的话,InnoDB隐式定义主键
④InnoDB的键尽量选择有序的id,不建议UUID,MD5,HASH,字符串作为主键
3.3.2非聚簇索引(二级索引,辅助索引):非主键构建的B+树
概念:
如果使用非主键字段进行查找,可以多建几棵B+树,每个树采用不同的排序规则。比如c2的列,进行查找。按照非主键列建立的B+树需要一次回表操作能定位到完整的用户记录,这种B+树是二级索引。
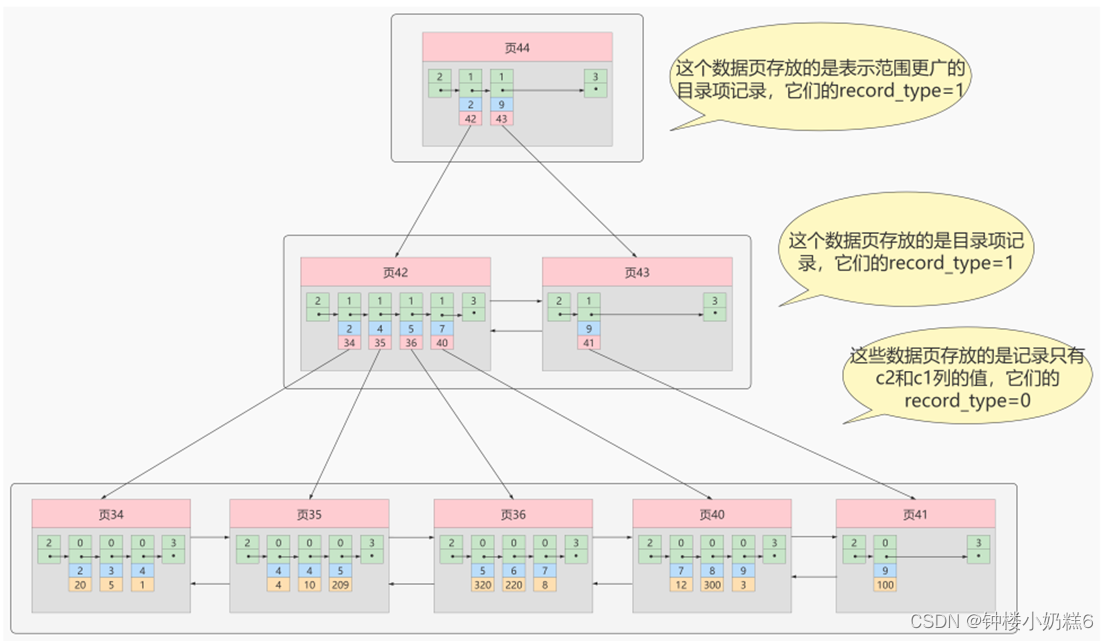
叶子节点,数据页里面的数据按照c2的大小排序成单链表。用户记录不完整,存c2和主键项。
回表:(回聚簇索引)
根据c2的列(非主键列)大小排序的B+树,只能找到查找记录对应的主键值,二级索引没有完整的用户记录,所以需要到聚簇索引根据查找出的主键值再查一遍。这个过程就是回表。所以从非主键列条件查找一条记录需要2棵B+树
为什么要回表操作,把完整的用户记录存放到二级索引的叶子节点不行吗
太占内存空间。冗余大
一张表有1个聚簇索引和多个非聚簇索引。
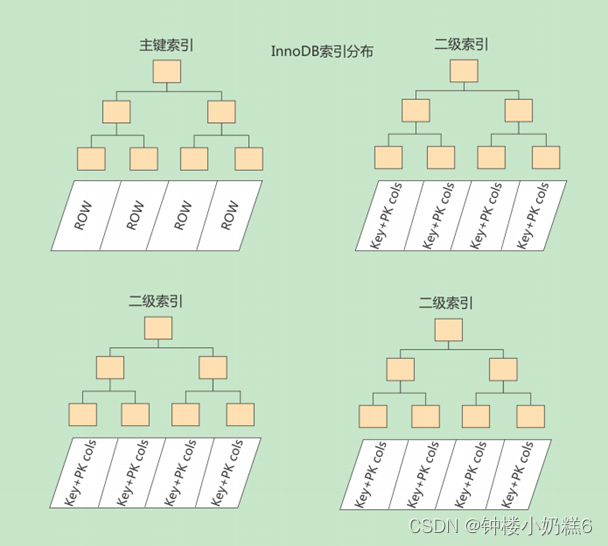
3.3.3联合索引:多个列作为排序规则,c2,c3组合

概念:
①把各个记录和页按照c2进行排序
②在c2列相同情况下,采用c3进行排序。
③本质上是二级索引,需要回表操作
④叶子节点用户记录是c2,c3和主键c1构成
3.4InnoDB的B+树索引的注意事项
3.4.1根页面内存位置万年不动
B+树的形成过程:
①当创建一个表的时候,底层为这个索引创建一个根节点,此时没有目录项和用户记录
②向表中插入数据时,先存储在根节点

③当根节点空间用满时(假设3条),此时根节点成为目录页复制一个新页(页a)
④再插入一个数据时,通过页分裂操作,得到页b。
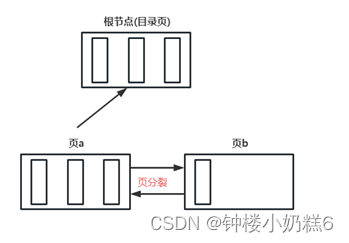
⑤随着插入操作,叶子节点变多,目录项空间满了。此时根节点复制一个新目录页a
⑥当进行插入的时候,会把目录项存放到目录页b

当InnoDB用到这个索引的时候,都会从固定的地址找到这个根节点的页号,从而访问这个索引。
3.4.2内节点中目录项记录的唯一性(除了非叶子节点)
①B+树索引的内节点目录项是索引列+页号。假设一个表的数据是

构建的二级索引B+树,如过插入一条数据 (8,1,’c’),就不知道是插入页4还是页5了。造成了目录项记录不唯一

②解决方法是目录项加入主键:索引列+主键值+页号

3.4.3一个页面最少存储2条记录
四、MyISAM中的索引方案:B-Tree索引
1.介绍
MyISAM引擎使用B+Tree作为索引结构,但是叶子节点的data域存放的是数据记录的地址
2.原理
InnoDB中索引就是数据。但在MyISAM中索引和数据分开存储,非聚簇索引

①数据文件:用户记录的插入顺序单独储存的一个文件。不分页。不按照主键大小排序。不能使用二分法查找
②索引文件:存放索引信息的,为表中的主键创建一个索引。叶子节点存放的是主键值+数据记录的地址
3.MyISAM和InnoDB的对比
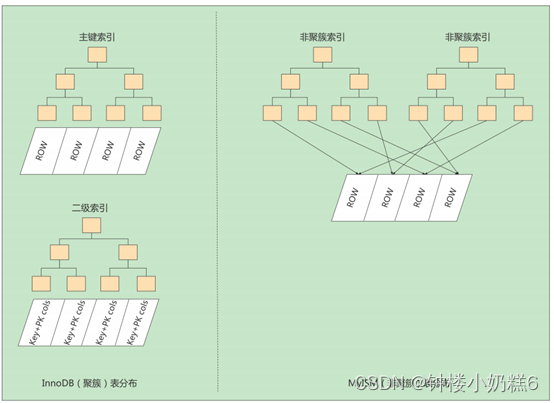
MyISAM的索引方式是“非聚簇的”,InnoDB包含1个聚簇索引
①在InnoDB中根据主键值对聚簇索引进行一次查找就能找到对应的记录。在MyISAM(非聚簇,二级索引)需要一次回表操作。
②InnoDB数据文件就是索引文件,索引即数据。但是MyISAM的数据文件和索引文件是分离的,索引文件保存的是数据的地址
③InnoDB的非聚簇索引的data域存放的是主键的值,而MyISAM存放的是记录的地址。
④MyISAM的回表十分迅速,拿着地址直接找数据。但InnoDB通过获取主键后在聚簇索引查找记录。
⑤InnoDB要求表必须有主键,MyISAM可以没有。在InnoDB如果没有指定,MySQL自动选择一个非空且唯一做主键。如果不存在这种类型,MySQL自动为InnoDB隐含字段做主键。
五、索引的代价
空间上代价
每次建立索引都是建立B+树,每一棵B+树的节点都是数据页。一个数据页默认16KB,许多数据页组成,就是一大片存储空间
时间上代价
每次对表中的数据增、删、改需要修改B+树的索引。B+树的节点按照索引列的值从小到大顺序排序双向链表。存储引擎需要额外的时间进行一些记录移位,页面分裂、页面回收等操作来维护好节点和记录的排序。
六、MySQL为什么选择B+树
选择标准
能让索引的数据结构尽量减少磁盘的I/O操作次数。索引是存储在外部磁盘上的,只能逐一加载到内存。MySQL衡量查询效率标准就是磁盘IO次数
1.Hash结构:数组+链表
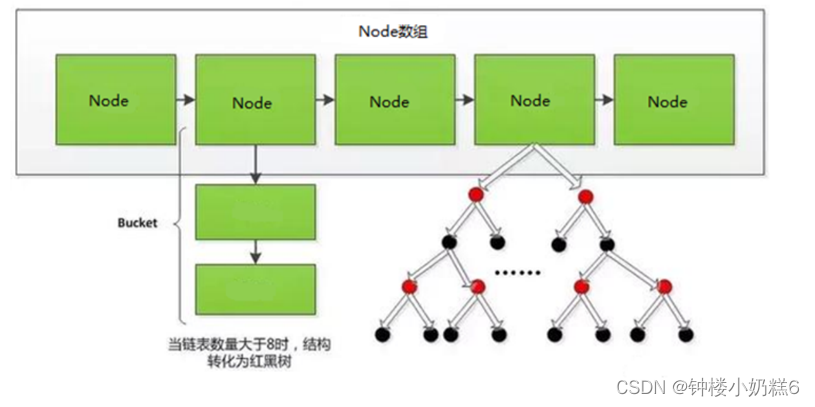
问题1:为什么Hash效率高,索引结构使用的是树形呢?
①Hash索引仅能满足等于,不等于,in的等值查询。如果是范围查询,时间复杂度是O(n),树形是有序的,保持高效率
②Hash索引的缺陷是没有顺序的,order by 排序时要重新排序
③对于联合索引,Hash值是一起计算的,无法对单独一个键或几个索引键查询
④Hash索引不适合在重复值多的列上,比如性别,年龄。因为遇到Hash冲突时,需要遍历桶中的行指针进行比较,找到查询关键字非常耗时。
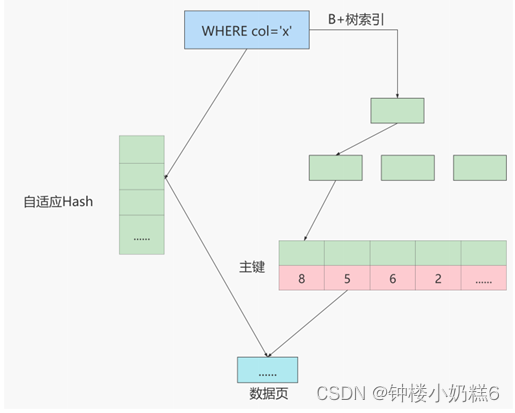
问题2:什么是InnoDB自适应的Hash索引?
如果某个数据经常被访问,当满足一定条件,当前的数据页地址就会放到Hash表中,当下次查询时,直接到找个页的位置。B+树也有了Hash的优点
2.二叉搜索树
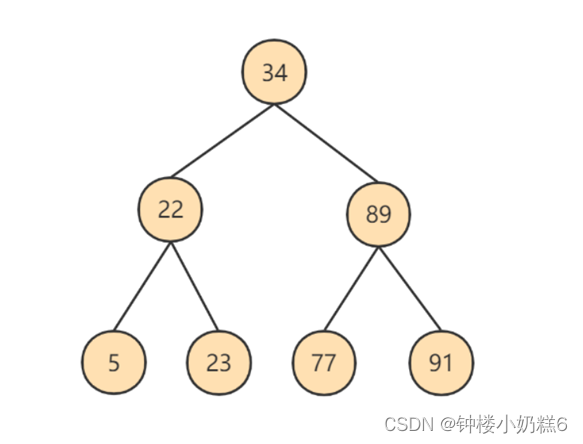
磁盘的IO次数跟索引树的高度是相关的。
为了提高查询效率,就需要 减少磁盘IO数 。为了减少磁盘IO的次数,就需要尽量 降低树的高度 ,需要把原来“瘦高”的树结构变的“矮胖”,树的每层的分叉越多越好。
3.AVL树:平衡二叉树
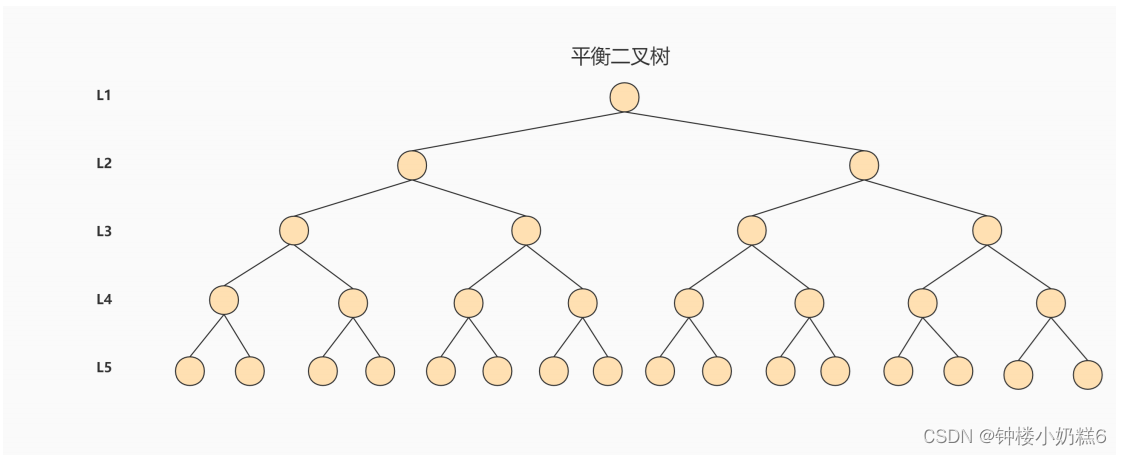
针对同样的数据,如果我们把二叉树改成 M 叉树 (M>2)呢?当 M=3 时,同样的 31 个节点可以由下面的三叉树来进行存储:

4.B树:非叶子节点存放的也是数据
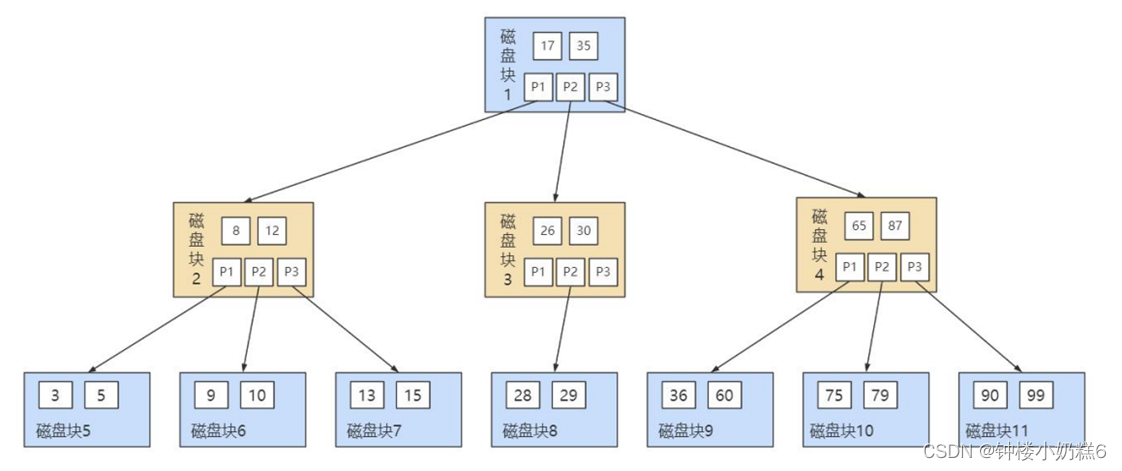
查找的关键字是 9步骤:
①与根节点的关键字 (17,35)进行比较,9 小于 17 那么得到指针 P1;
②按照指针 P1 找到磁盘块 2,关键字为(8,12),因为 9 在 8 和 12 之间,所以我们得到指针 P2;
③按照指针 P2 找到磁盘块 6,关键字为(9,10),然后我们找到了关键字 9。
5.B+树

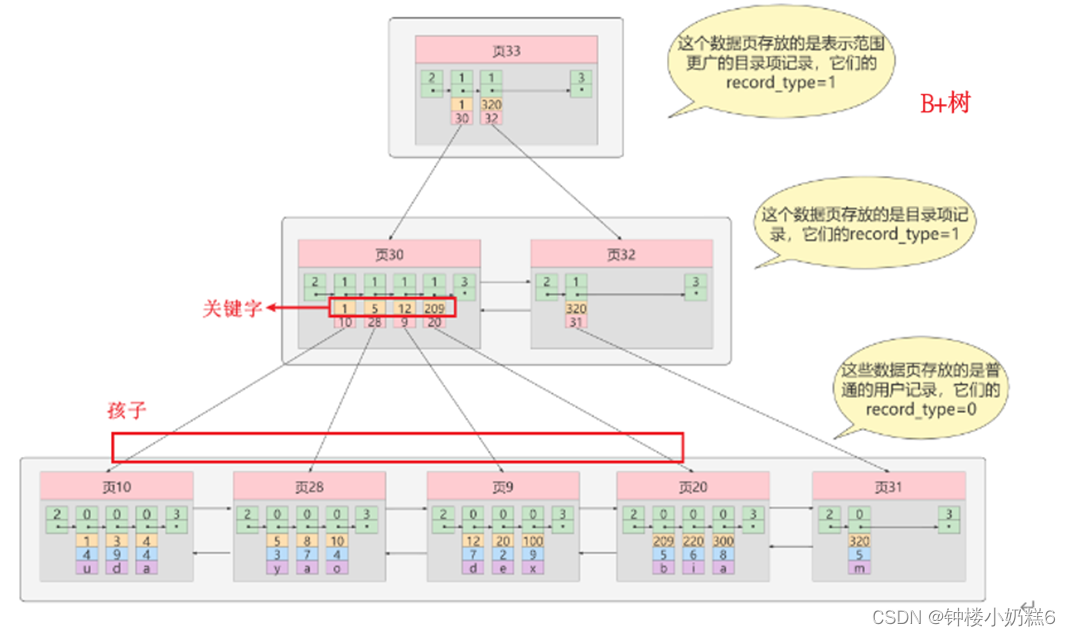
问题1:B+树和B树的区别
①B+树有K个关键字就有K个孩子,B树有K个关键字,孩子是K+1
②B+树中只有叶子节点存数据,B树叶子节点和非叶子节点都存放数据
③B+树所有的关键字都在叶子节点出现,构成一个有序链表,按照关键字从小到大排序。
问题2:为什么B+树非叶子节点不存放数据,好处是什么
①B+树查询效率更稳定:B+树访问到叶子节点才有数据,但是B树非叶子节点和叶子节点都有数据,查询不稳定
②B+树查询效率更高:B+树比B树更矮胖。查询IO次数少,B+树存储更多的节点关键字
③在查询范围上,B+树效率比B树高。B+树的数据都在叶子节点上,而且数据递增的。B树需要遍历才能完成查找,效率低。
问题3:为了减少IO,索引树会一次性加载吗?
①数据库索引是存储在磁盘上的,如果数据量很大。索引会很大,超过几个G
②当利用索引时,不能把几个G的索引加载到内存。逐一加载到每一个磁盘页,磁盘页对应着索引树的节点。
问题4:B+树的存储能力如何?为何说一般查找行记录,最多只需1~3次磁盘IO
InnoDB的存储引擎中页的大小为16KB,一个页大概存储1000个键值。深度为3的B+可以维护10亿条记录
实际情况每个节点不可能填充满,因此数据库中2-4层(包含根节点),因为根节点就在内存,所以只需1-3次磁盘的IO操作。
问题5:为什么说B+树比B-树更适合实际应用中操作系统的文件索引和数据库索引?
(回答B+树的优点)
①B+树查询效率更稳定:B+树访问到叶子节点才有数据,但是B树非叶子节点和叶子节点都有数据,查询不稳定
②B+树查询效率更高:B+树比B树更矮胖。查询IO次数少,B+树存储更多的节点关键字
③在查询范围上,B+树效率比B树高。B+树的数据都在叶子节点上,而且数据递增的。B树需要遍历才能完成查找,效率低。
问题6:Hash 索引与 B+ 树索引的区别
①Hash索引不能范围查找,B+树可以。Hash数据是无序,B+叶子节点是有序链表
②Hash索引的缺陷是没有顺序的,order by 排序时要重新排序。B+叶子节点是有序链表
③对于联合索引,Hash值是一起计算的,无法对单独一个键或几个索引键查询,B+树可以
④InnoDB不支持哈希索引
问题7:Hash索引与 B+ 树索引是在建索引的时候手动指定的吗?
根据MySQL的存储引擎决定的。
InnoDB和MyISAM存储引擎是B+树索引,但InnoDB提供自适应的Hash
Memory/Heap和NDB存储引擎,可以选择Hash索引